这篇论文主要围绕当前MoE模型在多GPU集群下推理优化展开,针对当前MoE模型存在的一些不足,以及现有多GPU集群下MoE推理优化技术的缺陷展开,提出了新一代HARMOEny技术。
一、What is MoE?
首先什么是MoE模型?当前(截至2026)深度学习领域使用的主流框架还是Transformer模型,如下图所示:
该架构由左侧的Encoder和右侧的Decoder模块组成,其中Encoder和Decoder内部又由多个Encoder Layer和Decoder Layer构成。但是随着GPT技术的爆火以及现阶段AI技术的演进,我们逐渐使用Decoder only的架构取代了Transformer。
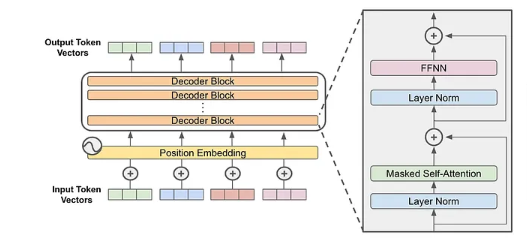
但现有的Decoder only的架构也有问题,即该模型对于算力的要求极高,同时能源要求也很高,论文中也指出“NVIDIA and AWS estimate that up to 90% of the ML workloads are serving deep neural network models”。
针对这一算力和能源瓶颈,学术界新提出了MoE结构。下图左侧就是Decoder only,右侧为MoE的结构,只是将其中的Feed-Forward Network(FFN)层替换为了MoE层。
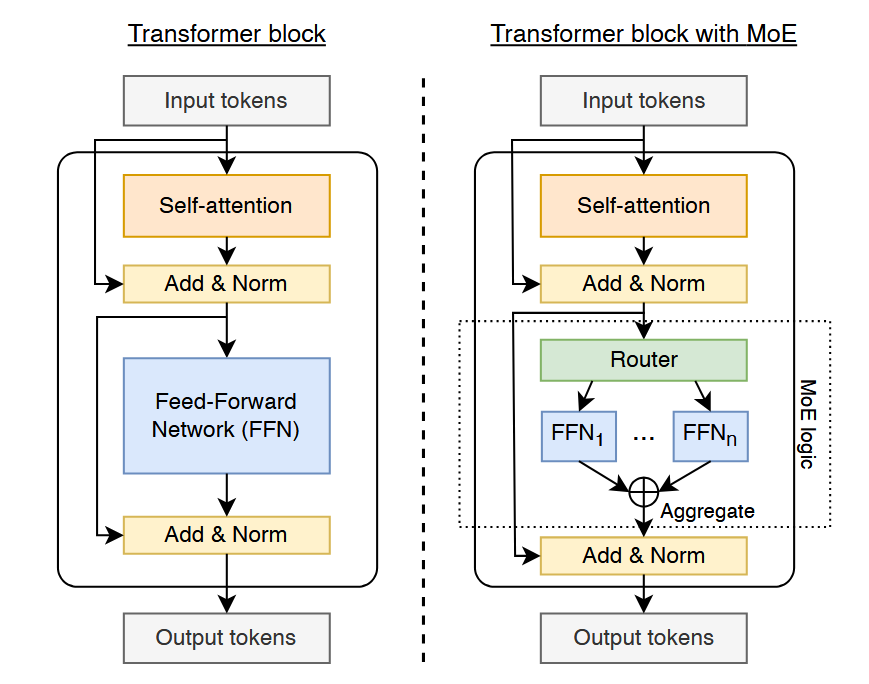
首先我们需要明确一个概念,在论文中提出“The FFN is the most timeconsuming part of the transformer block”,FFN是整个Transformer block中计算最耗时的部分。该部分需要进行海量的矩阵乘法,但是MoE提出了Router + expert的概念,通过将原本庞大的FFN分成若干个小的expert(或者我们也可以叫他小FFN),利用router对进入的request选择适合的expert,减少作用意义不大的FFN计算。
其实在我看来,整个MoE的部分就类似于我们在训练模型过程中会发生的dropout,只不过当前的dropout是有选择性的,而非随机dropout。
这样看的话,貌似已经解决了深度学习的算力和能源问题,我们直接开训吧。
二、why HARMOEny?or what is moe drawback?
MoE的优势确实很明显,我们可以有选择性的激活一部分expert进行计算,而极大的减少了全量计算带来的开销。利用这一特性,我们可以训练出更大规模的模型,而不需要更多规模的算力。
但是这又会存在着一个新的问题,即GPU的显存需求会不断攀升。我们要知道的是,虽然我每次只激活一部分expert做计算,但是所有的expert都需要在显存当中,一旦被选中就需要立刻执行。这就会引出了一个问题,算力需求少,但是显存需求大。
而且另一个问题是,就像人一样,expert一定也会有擅长和不擅长的事情。可能一个expert擅长回答医学领域的问题,所有的医学问题都会涌向整个expert;而另一个expert擅长法律,那么法律领域问题也会一起选择该expert。这就导致了会出现hot expert和cold expert的概念,可能一个expert一直忙碌,而另一个expert却一直空闲。旱的旱死,涝的涝死。在多GPU集群下,该问题则会更加严重。
如下图所示,以一个switch model为例,模型的一层有6个expert,假设在某GPU集群下,有3个GPU负责该MoE部分。那么expert1、2在GPU0上,expert3、4在GPU1上,expert5、6在GPU2上。当有6个request的中间结果token到达该MoE部分时,根据Router的选择,t3需要由expert1处理,t4需要由expert2处理,t2需要由expert3处理,t6需要由expert4处理,t5需要由expert5处理,t1需要由expert6处理。
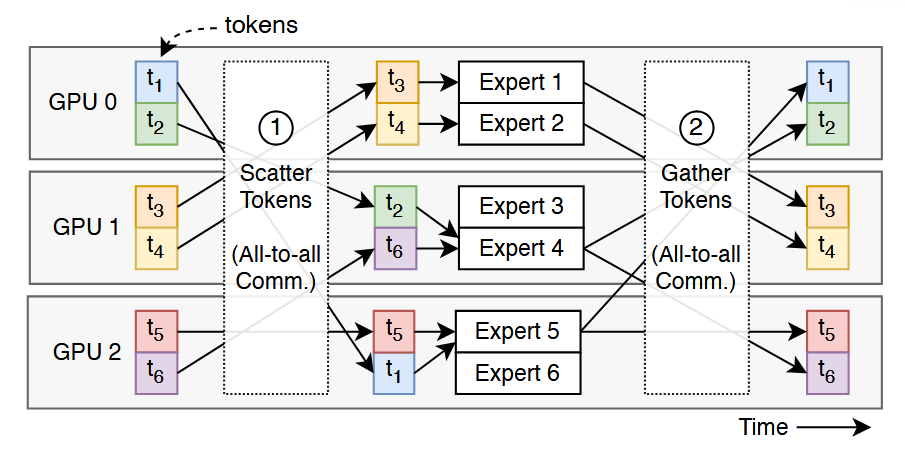
我们在处理这些token前和处理token后,需要进行两次全局通信。即在处理前,需要将GPU0、1、2上计算完成self-attention的结果token,进行全局的传输,使得每个GPU上的expert都能获取到需要进行处理的request。在MoE计算完成之后,又需要将token传回到之前计算self-attention的卡上去。这样看貌似还能接受,但是如下图所示,当这些request都选择了GPU0上的expert1(即产生了hot expert问题之后),GPU1和GPU2上没有任务或者任务很少,计算时间很短,更多是在等待GPU0计算完成,进行同步通信。
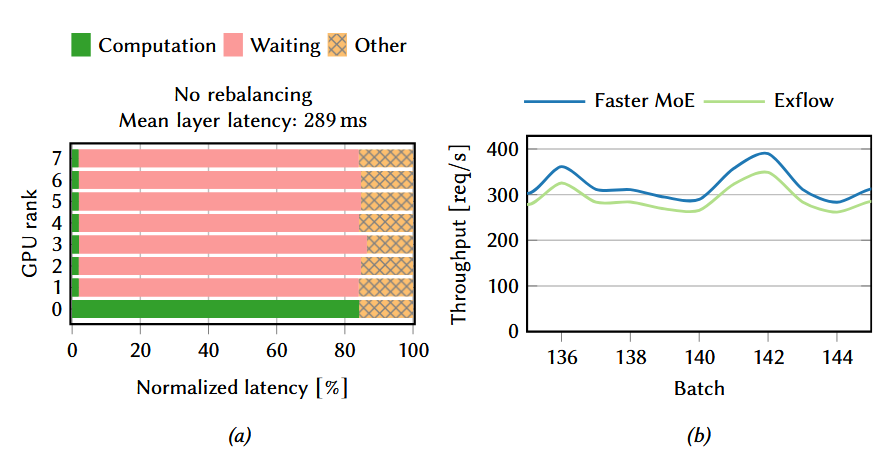
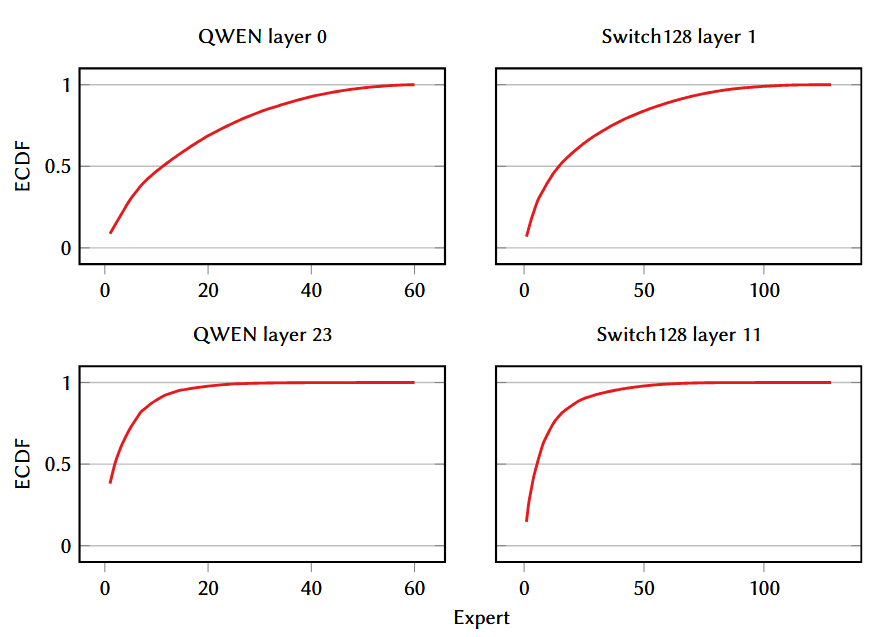
这两点就是当前MoE存在的最大的问题。下图所表示的ECDF中可以看到,其实取不到10个hot expert就能够处理50%以上的token,结合之前所阐述的问题,其实就是hot expert严重拖慢了计算时间。
那肯定也有一些办法考虑过解决或者缓解这个问题,论文中提到它们的主要思路可以分为两点:They either resort to replication [13] of popular experts or collocate popular experts across MoE layers [23, 38].
3.1、hot expert replicate
我们一个很朴素的思想就是,将原本的hot expert多复制几分,放到不同的GPU上去,再加上负载均衡的技术,就可以极大的缓解之前hot expert带来的问题。
3.2、collocate popular experts across MoE layers
这个技术相对来说稍显复杂。我们知道一个模型是由多个layer所构成的,那如果我们将每一层的hot expert都放到同一个GPU上呢?
暂时先忽略不同层的request同时请求同一个GPU的情况,我们只考虑request是同步执行的这个情况。那就会出现,一个request在多层之间不需要跨GPU进行MoE计算了,只需要在上一层(也就是当前所在的)GPU上执行本层的MoE即可,这样极大的减少了跨GPU的传输。
理想很美好,但是现实又给我们出了一个难题。前文提到过hot expert是相对于不同领域的request而言的,如果request的领域经常变化(即许多用户同时向我们的多GPU集群上的MoE模型提问)的话,这个hot expert是时刻变化的,之前的技术更多是固定领域request分析得出的,很明显与我们现实的服务出现了不一致。
三、what is HARMOEny?
那如何解决这一问题呢?作者在这篇论文当中提出了HARMOEny的框架,其中两个核心技术创新点就是token rebalancing和expert prefetch。
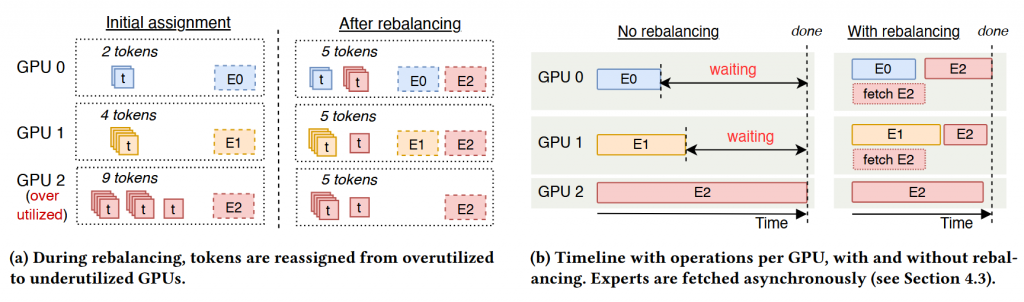
token rebalance如上图所示,a中左侧是未开启token rebalance时,token和GPU、expert的对应情况,而右侧是开启token rebalance和expert prefetch后,token和GPU、expert的对应情况。我们由b中可以明显的看到,通过token rebalance和expert prefetch极大的缩减了MoE服务所需的时间。
3.1、token rebalance

具体算法如上图所示,首先会从GPU集群当中取出后续要处理最多request的目标GPU,并获取到要给该目标GPU传输request最多的源GPU,最后再获取从该源GPU到目标GPU之间request选择最多的专家以及对应该专家从源GPU传输到目标GPU的request数量。
判断request数量是否大于q(提前设定好的超参数阈值,q的值我们将在下面说明如何计算),如果小于q的话,说明该行为已经不会有收益了,到此结束。如果大于q的话,从GPU集群当中取出后续要处理最少request的要迁移的GPU,取迁移GPU中剩余的request容量(平均每个GPU上应该有多少request和自身实际request的差值)与request数量的最小值,将这部分request放到迁移GPU上。更新GPU集群的状态,再次循环,直到不会再产生收益。
3.2、expert prefetch
执行完token rebalance,我们会发现一个新的问题,就是rebalance后的token,可能会出现为token选择的GPU并没有它所需要的expert。这和过日子不一样,不能将就凑活。
那我们就需要考虑把expert再拉取到当前GPU上。在同一个GPU上,一边执行expert1的token计算,一边拉取需要的expert2,就叫做expert prefetch。如果epxert1执行的时间刚好的话,那expert1执行结束,立刻就能执行expert2,而不用等待再去拉去的时间。通过这样的流水线即可掩盖时间,提高单位时间的吞吐量。
另外有一个优点,就是我们在这里就可以放心的将expert放到CPU内存里,而不需要一直将所有的expert都放在GPU显存当中,占用资源了,也极大地缓解了显存开销。
关于阈值q的设定,就是为了request的数量足够大,可以掩盖住prefetch expert的时间而设定的。设|O|为执行特定专家所需的浮点运算次数,φ为所用GPU的每秒浮点运算能力,|E|为单个专家的存储大小(字节),β为PCIe带宽(字节/秒)。
专家模块通常为双层MLP,其中第一层权重矩阵W1的维度为m×p,第二层W2为p×m。另设d_type为W1或W2中单个元素的字节大小,q为专家处理的令牌数量。专家计算可表示为xW1W2(其中x为输入令牌),因此专家参数大小|E| = (mp + pm)dtype。完成具有q个令牌的专家计算所需操作次数为|O| = qp (2m − 1) + qm(2p − 1)。为掩盖加载专家的时间,得到q> (φ · dtype) / 2β。
3.3、HARMOEny

最终HARMOEny的流程如上所示,总共分为六步。
第一步通过router获取正常的token到expert、gpu之间的映射。
第二步我们不直接传输所有的gpu、expert和request信息去同步,那样容易造成大量的同步开销。反其道而行之,我们只传输部分meta信息,在GPU上拼凑出所有的expert、gpu和token之间的关系,做一次全局负载感知。
第三步进行token rebalance。
第四步则进行原本的token分发。
第五步进行expert的处理和prefetch。
第六步收集最终完成的token。
发表回复